Loading...
Back to Home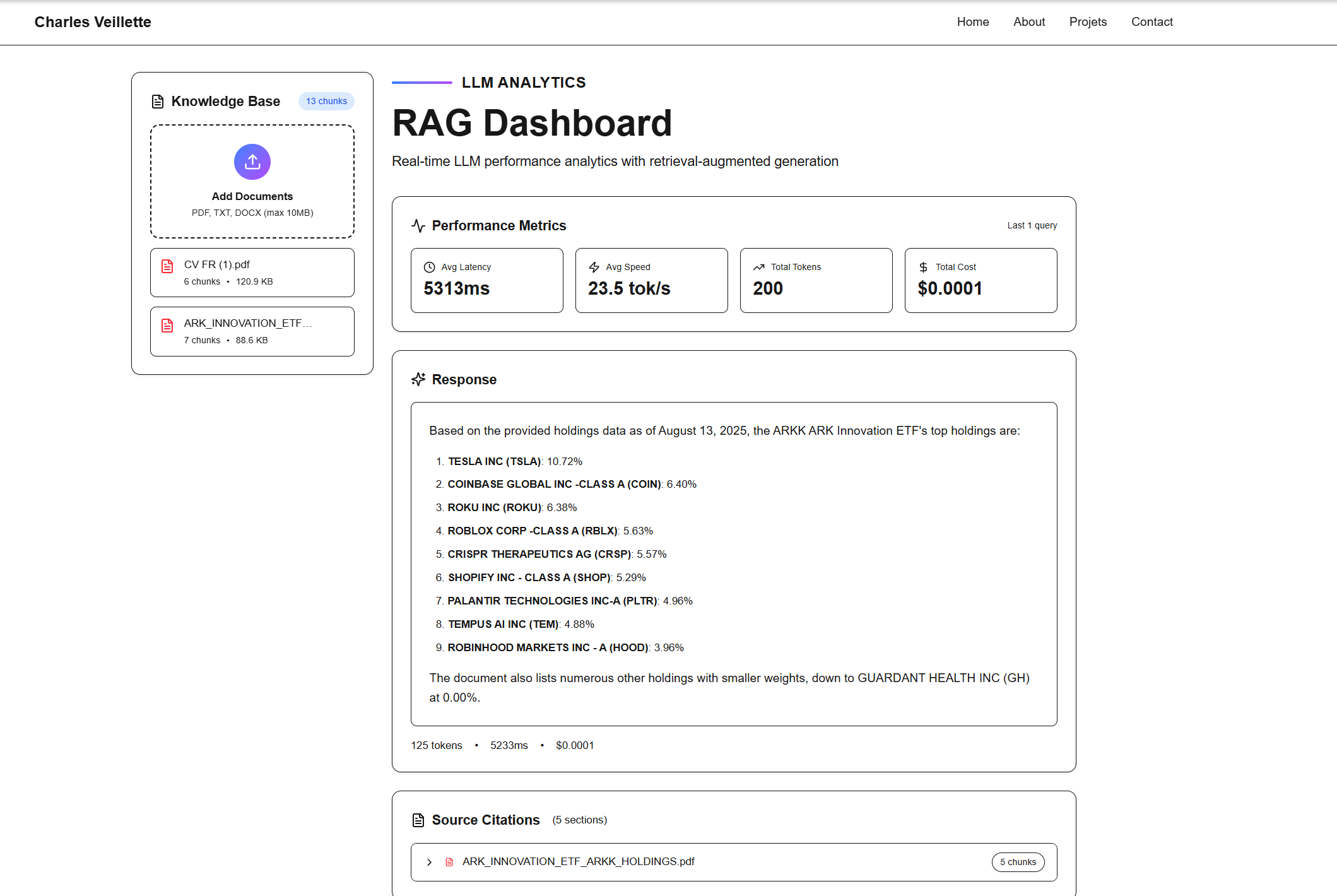
LLM Analytics Dashboard
Real-time LLM performance dashboard with RAG capabilities and document analysis
LLMRAGAIAnalyticsDashboardWeb App
About This Project
An interactive dashboard showcasing real-time analysis of LLM (Large Language Model) performance metrics including token usage, latency, speed, and cost tracking. The platform features advanced RAG (Retrieval-Augmented Generation) capabilities, allowing users to upload documents (PDF, DOCX, TXT) which are automatically chunked and embedded using Gemini AI. The dashboard provides semantic search functionality to find relevant document chunks for queries, displays used sources with expandable sections, and supports multiple Gemini models (2.5 Flash and Pro). Built with Next.js, it features streaming responses, markdown rendering, and a modern, responsive UI.
Key Features
Real-time LLM metrics tracking (tokens, latency, speed, cost)
Document upload and automatic embedding generation
Semantic search with Gemini embeddings
Interactive chunk viewer with expandable sources
Support for multiple Gemini models (Flash & Pro)
Streaming responses with markdown rendering
Drag-and-drop file upload interface
Technologies Used
Next.js
React
TypeScript
Tailwind CSS
Gemini API
pdfjs-dist
mammoth
Framer Motion